


In this blog, I will describe Azure data factory and top-level concepts in Azure Data Factory. Then we will see the benefits of using Azure Data Factory. So, let's get started.
What is Azure Data Factory?
Azure Data Factory (ADF) is a cloud-based ETL and data integration service provided by Azure. We can build complex ETL processes and scheduled event-driven workflows using Azure Data Factory.
For example, imagine an e-commerce company that collects petabytes of product purchase logs that are produced by selling products in the cloud. The company wants to analyze these logs to gain insights into customer preferences, customer retention, active customer base, etc.
The logs are stored inside a container in Azure Blob Storage. To analyze these logs, the company needs to use reference data such as marketing campaign information, customer location & purchase details which are stored in the Azure SQL database. The company wants to extract and combine data from both sources to gain useful insights. In such scenarios, it is best to use Azure Data Factory for ETL purposes. Additionally, the company can publish the transformed data to data stores such as Azure Synapse Analytics, so that the business intelligence (BI) applications such as Power BI can consume it for storytelling and dashboarding.
ADF makes the process of creating a data pipeline easy by providing data transformations with code-free data flows, CI/CD support, built-in connectors for data ingestion, orchestration, and pipeline monitoring support.
Let’s move forward to see top-level concepts in ADF.
Top-level Concepts in ADF
1. Dataset: Datasets identify data within different data stores which are used as inputs and outputs in the Activity.
2. Linked Services: Linked Services define the connection information needed by the service to connect to the data sources.
3. Activity: Activity is the task that is performed on the data. There are three types of activities in ADF: data movement activities, data transformation activities, and control activities. For example, you can use a copy activity to copy data from Azure Blob Storage to Azure SQL.
4. Pipeline: A pipeline is a logical grouping of activities that together perform a unit of work. A data factory may have one or more than one pipeline.
5. Mapping data flows: The mapping data flow is executed as an activity within the ADF pipeline.
6. Integration runtimes: Integration runtime provides the computing environment where the activity either runs on or gets dispatched from.
7. Triggers: Triggers determine when a pipeline execution needs to be kicked off. For example, you can create a pipeline that gets triggered when a new blob arrives in the Azure Blob Storage container to copy data from Azure Blob Storage to Azure SQL.
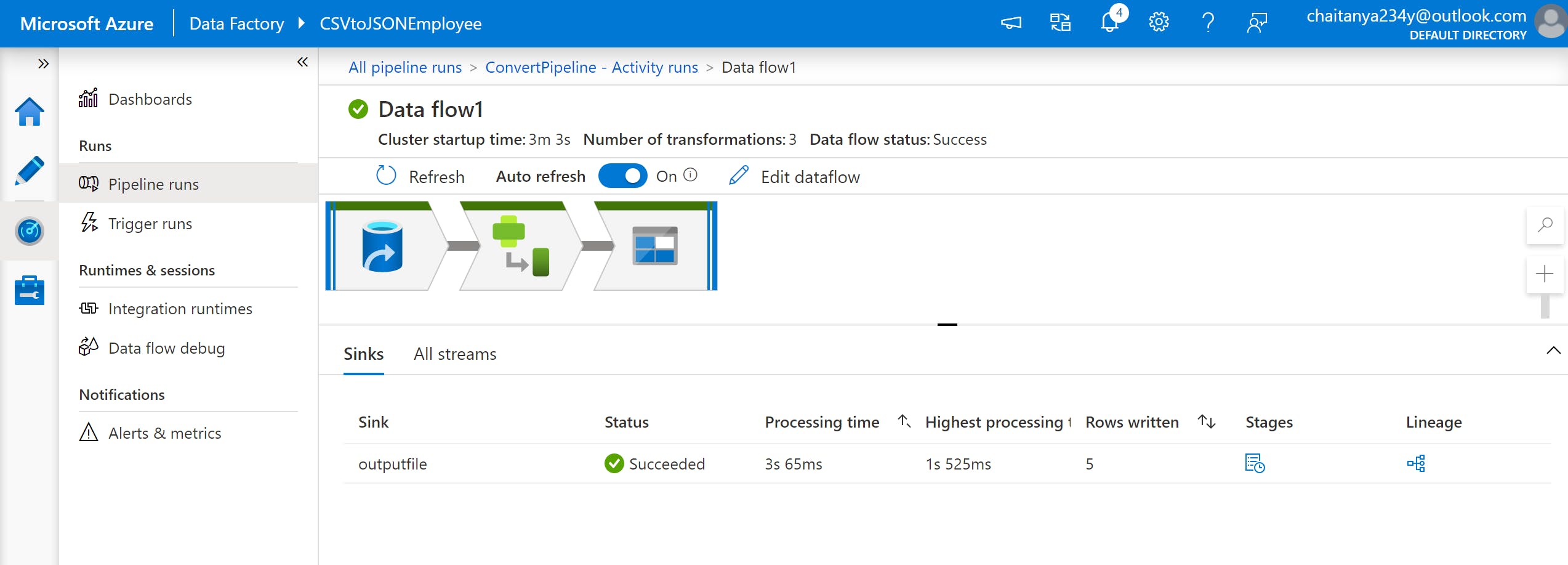
8. Pipeline runs: An instance of the pipeline execution is known as a Pipeline run.
9. Parameters: Parameters are defined in the pipeline and their values are consumed by activities inside the pipeline.
10. Variables: Variables are used inside the pipelines to store value temporarily.
11. Control Flow: Control flow allows for building iterative, sequential, and conditional logic within the pipeline.
Benefits of using ADF
1. Code-free data transformation: ADF provides mapping data flow to be executed as an activity in a pipeline. Mapping Data Flows provides a way to perform data transformation in the data flow designer. Thus, data transformation can be easily performed without writing any code.
2. Easy Migration of ETL Workloads to Cloud: ADF can be used to easily migrate workloads from one data source to another.
 3. Consumption-based pricing: Data Factory provides a pay-as-you-go pricing model and no upfront cost is required from the customer end.
3. Consumption-based pricing: Data Factory provides a pay-as-you-go pricing model and no upfront cost is required from the customer end.
4. Better scalability and performance: ADF provides built-in parallelism and time-slicing features. Therefore, users can easily migrate a large amount of data to the cloud in a few hours. Thus, the performance of the data pipeline is improved.
5. Security: User can protect their data stores credentials in the ADF pipeline by either storing them in Azure Key Vault or by encrypting them with certificates managed by Microsoft.
That's all, for now, I hope you got a good understanding of ADF and how you can use ADF top-level concepts for building an ETL pipeline. Hope this helps you to get started with developing ADF pipeline. Let me know in the comment section if you need any help in developing a pipeline using Azure Data Factory.